


Quality data is the foundation on which powerful AI models are built. AI systems learn by processing vast amounts of information, and the accuracy of their predictions or decisions depends on the quality of the data they are trained on. Data crowdsourcing has emerged as a critical solution to meet the growing demand for diverse, high-quality datasets that fuel AI applications. By leveraging a global workforce to gather and annotate data, crowdsourcing platforms enable companies to scale their AI training efforts efficiently. In this blog, we’ll explore some of the top data crowdsourcing platforms that can elevate your projects, offering insights into their particular strengths and ideal use cases.
What makes a “top platform”?
Ensuring that the training data used is accurate, relevant, and well-labelled is essential for the success of AI systems. However, data requirements vary by the nature and industry sector of different businesses, and like-for-like comparisons between data crowdsourcing platforms are difficult to make. A media company will have different requirements to a healthtech provider, which will be different to a financial services provider, and so on.
Is it the number of gig workers they have access to? Some platforms make a feature of the size of their networks of gig workers, others are reluctant to enter into comparisons with their rivals.
Is it how long they have been operating? How long a platform has been trading is an indication of how much time they have had to accumulate expertise and experience, and develop customer-centric processes. Though at the same time, newer providers may have focussed on a narrower range of services to accelerate their development of proficiency.
Is it the business/industry sectors they work in? Some data crowdsourcing platforms have become favoured for AI training within specific industries, and have developed greater insights into their requirements and how those particular types of businesses operate. This may not mean they can bring relevant insights and expertise to other sectors.
Our review of notable crowdsourcing platforms that provide data to train AI is therefore just a starting point for anyone seeking a supplier, and does not provide definitive answers of which platform for any set of particular circumstances. Anyone looking for data crowdsourcing platforms to work with should do their own analysis.
That aside, let’s look closer at a dozen platforms that are widely regarded as definitely worth consideration.
Top data crowdsourcing platforms for training AI
Amazon Mechanical Turk (MTurk)
MTurk provides access to a large and diverse global workforce to complete tasks like data labelling, surveys, and content moderation, crucial for big data projects. It was founded in
Organizations can harness the power of crowdsourcing via MTurk for a range of use cases, such as microtasking, human insights, and machine learning development. It is generally regarded as best suited to more menial elements of large scale data labelling for AI and machine learning models, large-scale survey distribution for market research or academic studies, and content moderation and filtering tasks. Also, product categorisation and tagging for e-commerce, and transcription of audio and video files at scale.
In India, Apollo Hospitals used MTurk for crowdsourcing collective intelligence to categorise and tag medical images for research purposes, significantly reducing processing time and cost.
Clickworker
Clickworker offers data categorisation, annotation, and collection services through a vast pool of contributors, with a particular focus on supporting AI training with high-quality labelled data. It launched in 2005 and claims a large global network of over 6 million gig workers.
Ideal use cases include e-commerce product categorisation and content creation, data tagging and annotation for AI and machine learning projects, and large-scale surveys and market research studies. Also, image and video annotation for visual recognition systems, plus sentiment analysis and data validation tasks.
Communication with gig workers can be limited and quality control may require additional oversight. Platform fees can easily mount up for complex projects.
TELUS International (AI)
TELUS International supports large-scale data annotation and linguistic services, and claims a broad network of contributors across the globe. It was founded in Vancouver, Canada, in 2005. It builds and delivers next-generation digital solutions to enhance the customer experience (CX) for global and disruptive brands, supporting the full lifecycle of its clients’ digital transformation journeys.
Its relatively broad capabilities cover digital strategy, innovation, consulting and design, digital transformation and IT lifecycle solutions, data annotation and intelligent automation, and omnichannel CX solutions, including content moderation, trust and safety solutions, and more.
In its lifetime, Telus has completed over 20 acquisitions, with an average acquisition amount of $1.31B, to provide proven expertise in its wide range of services. The acquisitions listed in the previous link do not include Lionbridge AI, which focussed mainly on translation and testing services and announced its merger with TELUS International in March 2021.
TELUS International partners with brands across high growth industry verticals, including tech and games, communications and media, eCommerce and fintech, healthcare, and travel and hospitality. It is currently rebranding itself as TELUS Digital.
On the downside, because TELUS Digital is geared up for major companies it can be costly for smaller ones. It also has a lengthy onboarding and project setup process, and can be slower for high-volume, fast-turnaround tasks. This is why users have to understand their goals when they start to look for data crowdsourcing platforms to work with.
Appen
Appen launched in 1996 in Australia and claims a network of more than one million gig workers around the world, operating in 265 languages in 170 countries. It offers an AI-powered platform for automated collective intelligence applied to data labelling and data enrichment, and enables businesses to process and improve large datasets efficiently by tapping into its global crowd of contributors.
It is ideal for high-quality training data for machine learning and AI projects, particularly multilingual natural language processing (NLP) data collection and image, text, and speech annotation and translation services for AI development. It is also suitable for sentiment analysis and content categorisation for social media analysis.
In the healthcare sector, for instance, Appen provides specialised medical image annotation and analysis platforms, leveraging crowdsourced expertise for tasks like tumour detection and drug efficacy assessment. An example of Appen using NLP and AI to improve healthcare is Winterlight Labs, which has created a tool that can monitor cognitive impairment through speech.
However, Appen can be relatively expensive for large projects, it has a slower turnaround time due to its quality assurance processes, and offers a less than straightforward pricing structure.
Prolific
Prolific is based in London, UK, and was founded in 2014. It is a popular platform for crowdsourcing high-quality participants for behavioural research and large-scale surveys, particularly for academic and market research.
Its primary focus on surveys and behavioural research makes it less suitable for diverse data annotation tasks, and its smaller user base compared to other platforms limits its scalability for massive projects. Its high quality of gig workers also make it more expensive than traditional survey platforms.
Hive
Hive provides AI-powered data annotation and content moderation services, leveraging a global workforce to process millions of data points, particularly in media and tech industries. It limits itself to specific data types (e.g., video, image, and text moderation), and obviously this niche focus may not fit all data needs.
Its technology is transforming approaches to platform integrity/content moderation (including AI-generated content detection), brand protection, sponsorship measurement, context-based ad targeting, and more.
The business was founded in 2013 and is based in San Francisco, California. It has over 200 full-time employees globally, plus a distributed workforce of more than 5 million global contributors that supports data labelling operations.
Remotasks
Remotasks specialises in entry-level data labelling, transcription, and 3D annotation. It connects companies with large-scale data needs to a global network of over 240,000 gig workers in 90 countries. Users have found that quality can vary without tight quality control measures and there is limited support for complex, customised tasks.
It was founded in San Francisco, California, in 2017.
Toloka
Originally developed by Yandex, a major Russian tech company, Toloka operates independently and is widely used across various industries as a global crowdsourcing platform that enables companies to collect and annotate large amounts of data for machine learning, AI training, and other data-centric projects. It leverages a vast global network of contributors to perform tasks such as data labelling, categorisation, transcription, and more. Its large pool of global gig workers in over 100 countries and operating in 40 languages make it ideal for scaling up data collection and annotation efforts quickly.
There are several built-in quality control tools, such as task overlap (multiple workers doing the same task to ensure accuracy), gold-standard tasks, and contributor skill assessments. These tools help improve the reliability of the data collected.
Toloka is well-suited for simple to moderately complex tasks, but for highly specialised or complex tasks (e.g., requiring expert knowledge or advanced linguistic skills), other platforms might be more appropriate.
Toluna
Toluna is more a market research platform that includes data collection. It provides access to a global community of millions of users who contribute to market research through large-scale surveys, product testing, and consumer feedback. It employs sophisticated targeting options for survey participants, though its primary focus on surveys can limit its use for diverse data collection.
It is ideal for large-scale consumer surveys and market research studies, product testing and feedback collection from global audiences, plus consumer insights and behaviour tracking for new product launches through demographically targeted panels. Its real-time data collection and analysis enable rapid decision-making in marketing and product development, though it can be expensive for large-scale survey deployments and results depend heavily on the quality of the survey design.
It is based in Connecticut, USA, and was founded in 2000.
LXT
Founded in 2010, LXT is headquartered in Canada with a presence in the United States, UK, Egypt, India, Turkey and Australia. Through its international network of contributors, LXT collects and annotates data across multiple modalities with the speed, scale and agility required by its clients to support machine learning, natural language processing, and other AI-driven applications.
LXT is strong in multilingual data and complex data annotation, and employs good project management and quality control processes. However, it offers limited flexibility in task types outside of AI/ML data annotation, and pricing can be steep for smaller projects. As you would expect, there is a longer onboarding process for customised tasks.
Their global expertise spans more than 145 countries and over 1,000 languages and sub-dialects.
TaskUs
TaskUs accesses over 100,000 gig worker ‘Taskers’ through the TaskVerse open platform’s community of freelancers, and uses them to provide clients with services including image and video annotation, audio transcription and tagging, text and image classification for social media, mapping for autonomous vehicles, menu translations, and more. It’s high-quality output with robust quality control through managed teams.
However, AI Services is just one part of its overall service offering. On LinkedIn it categorises itself as “Outsourcing and Offshoring Consulting.” It also provides customer experience management and support outsourcing for technology and e-commerce companies, digital content services including social media management and content creation, and enterprise-level back-office support for data entry, processing, and management.
It is focused on enterprise-level clients, and thus expensive for startups and small businesses.
TaskUs is based in Texas, USA, and was founded in 2008.
DataForce
DataForce supports a wide range of industries, including automotive, healthcare, finance, and technology, by delivering customised data solutions that accelerate AI development. It is good for collection and annotation of audio, image and text data, and provides comprehensive linguistic service – all to a high standard of quality.
It offers end-to-end AI data project management, and expert consulting services to help organisations design, implement, and optimize their data collection and annotation strategies. Where gathering sufficient real data is challenging, DataForce can create artificial data that mimics real-world data. This is especially useful for training AI models without compromising privacy.
DataForce is part of the TransPerfect family of companies, which claims to be the world’s largest provider of language and technology solutions for global business with offices in more than 100 cities worldwide. It is headquartered in New York.
Summary of key expertise for AI training
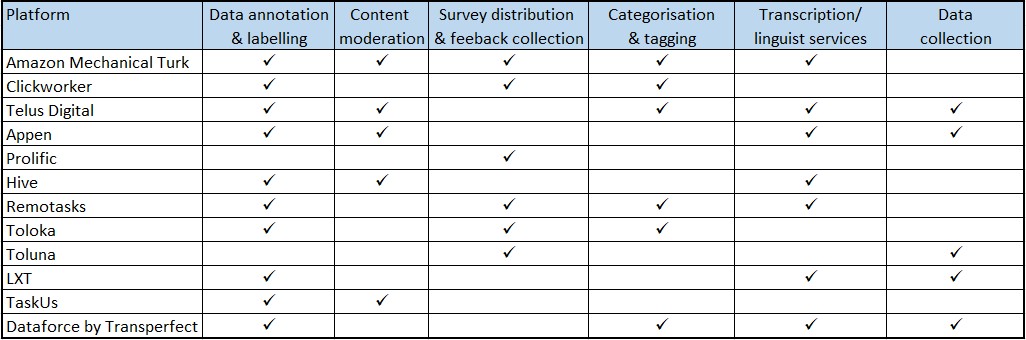
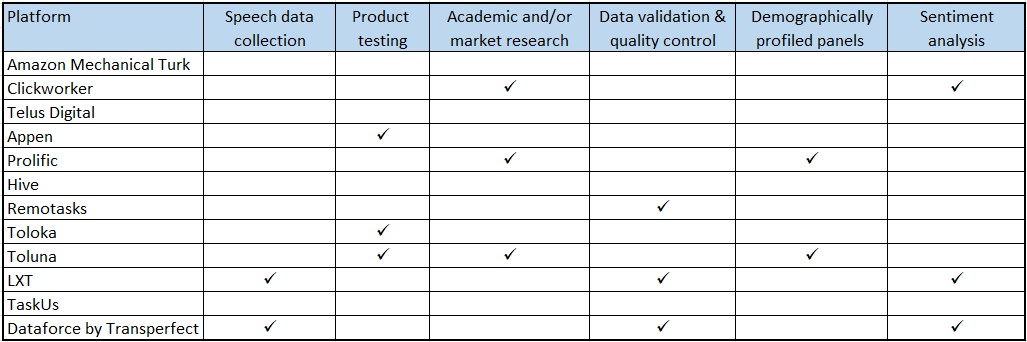
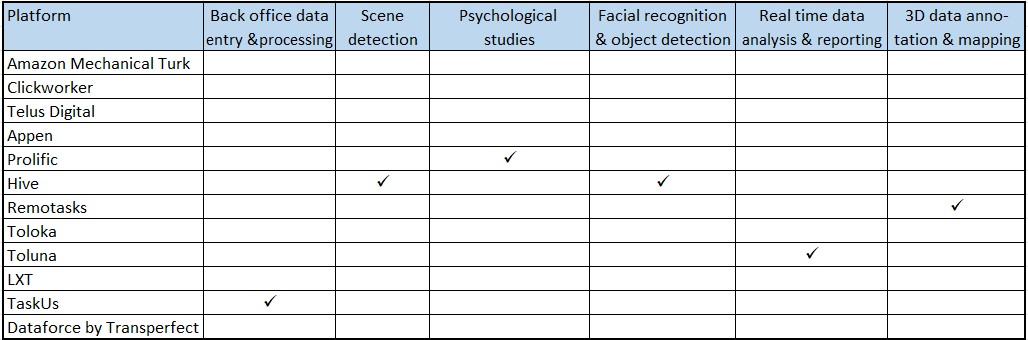
Check out What is Crowdsourcing? if you are new to the topic.



0 Comments