


A wide range of industry sectors are using speech technology, helping people to save time, improve effectiveness and efficiency, and ultimately even save lives. Key sectors where advances are being made include consumer durables, automotive, healthcare, banking and finance, and military defence.
To be clear, this article is about speech recognition: devices understanding and acting upon words that are spoken to them. It is not about voice recognition, which is about security to identify the person speaking.
How ASR works
ASR systems are a branch of Artificial Intelligence that converts spoken audio data into text, and uses sophisticated machine-learning algorithms. Machines scan the text and at lightning speed search a text database for how to best respond – what to do and what to say back.
Two measures of success rates are based on how accurately machines understand what is said to them, and then how successfully they respond with the correct response. Machine learning improves response success rates across time because correct response selection is based on an ever-growing number of occasions when users were satisfied. Though success rates of understanding what is said to begin with is closely linked to the quality of speech datasets that are used to train the automated service provider.
Sources of speech datasets
At the moment most of us have probably experienced speech technology on smartphones, or through Amazon’s ubiquitous Alexa Voice Service (AVS), which is used by many third party manufacturers of consumer electrical goods. Perhaps with an aim to expand its speech datasets, Google is beta-testing its “Task Mate” app in India. It is paying people to record translations between Hindi and English.
Why? Amazon wants to make it even easier to shop and spend money. Google wants to provide an easier user-interface to maintain its 92% share of the global search market (when including YouTube), among other objectives it may have.
Beyond the FAANGs’ efforts (Facebook, Amazon, Apple, Netflix and Google) there is a growing number of specialist speech dataset providers. DefinedCrowd has come to our attention through its use of crowdsourcing techniques. It has built its dedicated Neevo crowd of many thousands of people around the world in order to provide datasets in a growing number of languages that comprehensively cover varied accents and dialects. DefinedCrowd is now five years old, and a leading user of AI within crowdsourced speech recognition.
Sectors Applying Automatic Speech Recognition Technology
Consumer electrical goods
Manufacturers offer the prospect of a greater element of hands-free household management. Change room temperature, lighting, and choice of entertainment through verbal instructions. Ask the smart fridge for recipes while it’s ordering the automated weekly shopping, tell the coffee-maker what you want it to make for friends who drop in, let the oven set itself to cook a dish, or tell the washing machine what you’ve just put in it for it to select the best wash program.
Smartphone apps add an interface to implement speech-based control remotely.
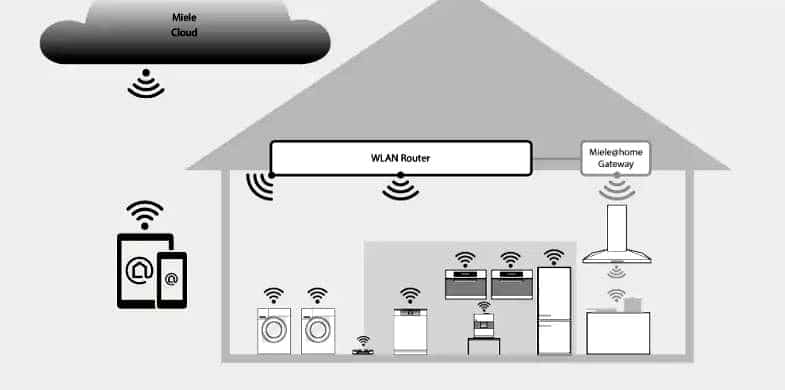
Image source: Miele
There are obviously particular benefits for handicapped or less mobile people. On the downside, people are becoming more aware of personal privacy issues. The data on your choices of how you live could find its way to a surveillance data marketplace, and be used to target you with messages that the senders hope will influence your behaviour.
In her book The Age of Surveillance Capitalism, Shoshona Zuboff referred to the Google-owned Nest thermostat. It offers to be the hub of a household digital ecosystem, with data gathered by every smart household device passing through it. A Nest thermostat could give a privacy conscious buyer a need to review up to nearly a thousand so-called “contracts” of burdensome terms of service for third-party data sharing related to their domestic equipment. The alternatives are to simply go along with it, or refuse. In the latter case, the Nest might not work to its full functionality, it wouldn’t receive updates, and there’s no promise all your equipment will work properly and follow your instructions.
Automotive
The automotive voice and speech recognition system market is forecast to be worth around US$39 Bn by 2027. The key goal is to deliver an improved, user-friendly environment for drivers and passengers through operating systems that execute certain acts by speech commands, such as open or close doors, switch headlamps on or off, indicate, and so on. It extends to infotainment systems, telephones, and navigation destination inputs. A major element of the improved environment is that it is a safer one where the driver doesn’t have to take their eyes off the road.
A new generation of self-sufficient and electric vehicles is expected to increase demand for voice recognition systems.
Speech recognition systems have to deal with ambient noise from inside and outside a vehicle, maybe with a car roof down. Each driver of a shared vehicle, and their passengers, may prefer operating in different languages.
Healthcare
Speech recognition is in high demand to record patient details. Hands-free devices enable medical staff to record notes while they operate equipment. In a given time frame they can give more information verbally than they would be able to write down. It can give healthcare professionals more time to actually interact with patients, and with colleagues to improve levels of collaboration.

Image source: Miele
Streamlining the admin workload is one thing, providing information to frontline service providers carries additional responsibilities. If speech recognition is going to be used in instances such as providing a surgeon with vital information in an operating theatre, or providing allergy data about a patient before administering or prescribing any medication, it has to be completely accurate in understanding what’s being said and in delivering an accurate response.
Specialised speech datasets used to train healthcare ASRs have to include every relevant medical and technical term.
Banking and other financial services
One of the most common uses of speech-based banking is allowing customers to check account balances, transaction history, and other account details. Going further than checking known data, payments companies such as PayPal and Venmo, and banks as diverse as the Royal Bank of Canada and the German mobile bank N26, allow for payments to be made through conversations with Siri. Westpac Banking Corporation in Australia integrated their services with Alexa to launch a new Amazon Alexa Skill called the Westpac Live.
Non-FAANGs AI and speech technology vendors such as Nuance, for example, are also assisting banks to establish speech and voice services. Nuance worked with USAA to launch a speech-activated banking app.
 Global banking brand BBVA operates a subsidiary in Turkey called Garanti, which launched a speech-based assistant called Mobile Interactive Assistance. It allows customers to make financial transactions by simply saying, “I need to transfer money to” and then add the name of the establishment to which they want to transfer the money. MIA also allows customers to find out exchange rates, buy or sell foreign currency, and carry out transfers. It is the most actively used customer service utilising voice recognition in Turkey.
Global banking brand BBVA operates a subsidiary in Turkey called Garanti, which launched a speech-based assistant called Mobile Interactive Assistance. It allows customers to make financial transactions by simply saying, “I need to transfer money to” and then add the name of the establishment to which they want to transfer the money. MIA also allows customers to find out exchange rates, buy or sell foreign currency, and carry out transfers. It is the most actively used customer service utilising voice recognition in Turkey.
Military defence
Speech recognition is used in military facilities to activate drones, aircraft and other systems. Whereas devices such as Alexa rely on network connectivity to cloud services with large, labelled datasets to learn and perform tasks for users, U.S. Army and academic researchers joined forces to develop a better way to interact and control autonomous systems such as mobile robots.
In combat situations, when personnel issuing the commands are likely to be highly stressed in perhaps noisy and fast changing circumstances, additional advanced technologies that measure the pitch of the voice, muscle activity and other salient criteria are acutely important.
According to the U.S. Army, a new conversational model called the Joint Understanding and Dialogue Interface (JUDI) “enables bi-directional conversational interactions between soldiers and autonomous systems.” Soldiers, maybe under attack, can’t be expected to have to remember specific ways of issuing particular commands. JUDI’s dialogue processing is therefore based on a statistical classification method that interprets a soldier’s intent from their spoken language – it has to correctly understand the motives or intent behind an order. It has also been trained with a speech dataset containing a high degree of “colourful language”!
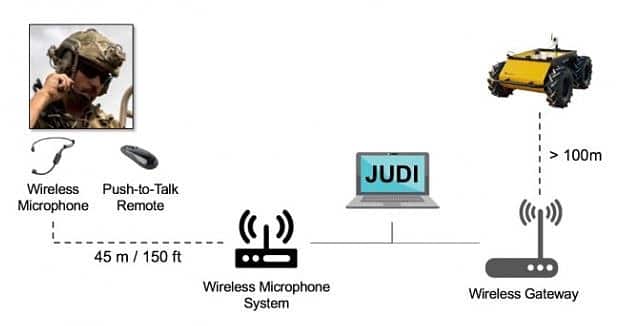
In addition to specific technical terminology, each business and industry sector has its own inherent factors that put particular pressures on speech datasets required to train ASR systems. Automatic speech recognition is an increasingly sophisticated technology, and there is limited scope for any providers of only “one size fits all” speech datasets.



0 Comments